
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 라즈베리파이
- pthread_join()
- scheduling
- socket
- i/o schduler
- 소켓 프로그래밍
- eureka
- Spring cloud
- position independent code
- 라즈베리파이 에러
- spring cloud eureka
- 리눅스
- jenkins pipeline
- Jenkins
- 젠킨스
- pthread_create()
- OS
- 소켓
- 젠킨스 파이프라인
- 우분투
- scheduler
- 스케줄링
- spring eureka
- 네트워크
- 스케줄러
- i/o scheduling
- MSA
- 포맷
- SD카드
- linux
- Today
- Total
dayne의 블로그
리눅스 I/O 스케줄러 종류 및 동작 과정 본문
목차
1. I/O 스케줄러의 필요성과 역할
2. Non-Multiqueue 스케줄러
3. Multiqueue 스케줄러
1. I/O 스케줄러의 필요성과 역할
시스템에서 I/O 작업이 발생하면, 가상 파일 시스템과 로컬 파일 시스템을 거쳐 I/O 스케줄러에 병합과 정렬을 통해 queueing 되고 순차적으로 블록 디바이스에 전달됩니다.

플래시 메모리를 기반으로 하는 SSD와 달리, HDD는 헤드의 물리적인 이동에 따른 지연이 발생하므로, 디스크 섹터를 이동할 때 I/O 요청을 최대한 처리해야 디스크 탐색 시간을 줄여 성능을 극대화할 수 있습니다.
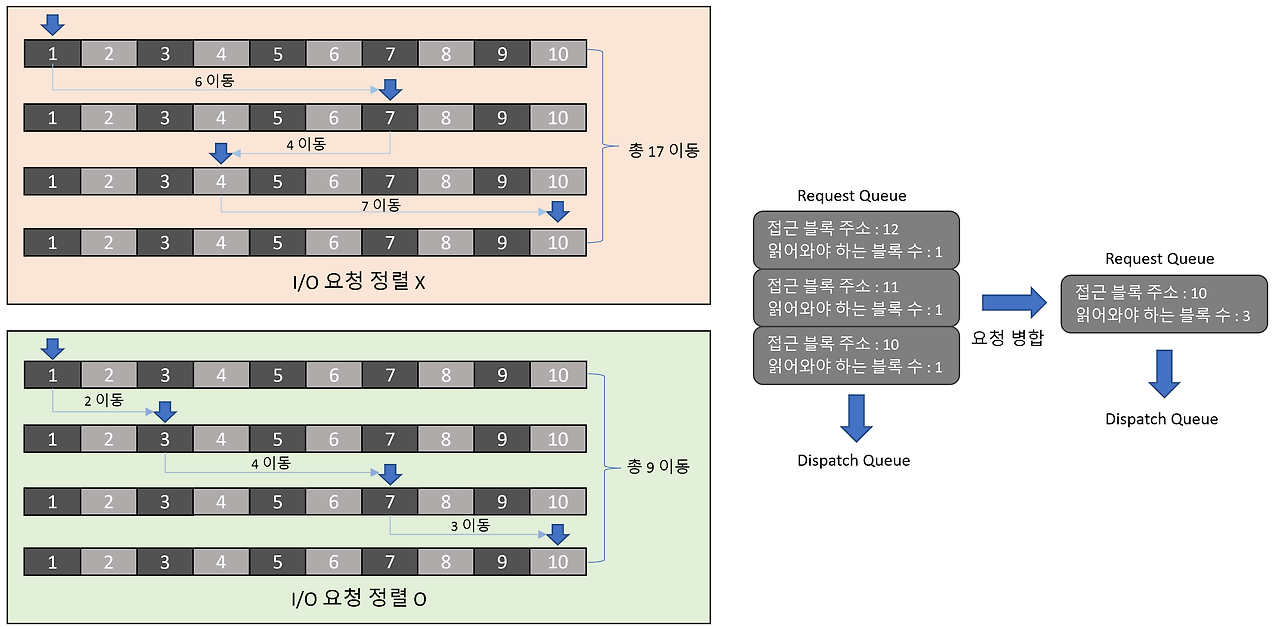
위의 예시처럼, 3개의 I/O 요청을 하나로 병합해서 정렬하였을 때, 디스크 헤더의 동선을 최적화할 수 있습니다.
I/O 요청을 병합하고 정렬하지 않은 경우, I/O 요청이 발생할 때마다 헤드가 각각에 대해 이동하여 데이터를 처리해야 합니다.
하지만 요청을 병합하고 정렬한 경우, 정렬하지 않았을 때보다 더 적은 헤드의 이동으로 모든 데이터를 처리할 수 있게 됩니다.
스케줄러의 방식에 따라 Non-Multiqueue 방식과 Multiqueue 방식으로 구분합니다.
Non-Multiqueue 스케줄러는 단일 FIFO 큐로 구현되어 있는 반면, Multiqueue 스케줄러는 I/O 요청을 저장 장치의 여러 queue에 동시에 매핑하여 병렬 처리를 합니다.
2. Non-Multiqueue 스케줄러
2.1 CFQ I/O 스케줄러 (Completely Fair Queuing)

cfq 스케줄러는 프로세스마다 각각의 queue를 가지며, 디스크의 대역폭에 따라 일정한 slice로 나누어 각 프로세스의 I/O 요청을 공정하게 처리합니다.
각 프로세스 큐에 들어오는 I/O 요청은 섹터(디스크 블록) 순서대로 정렬됩니다.
이를 통해 디스크 헤더의 이동을 최소화 시키는 것이 가능해집니다.
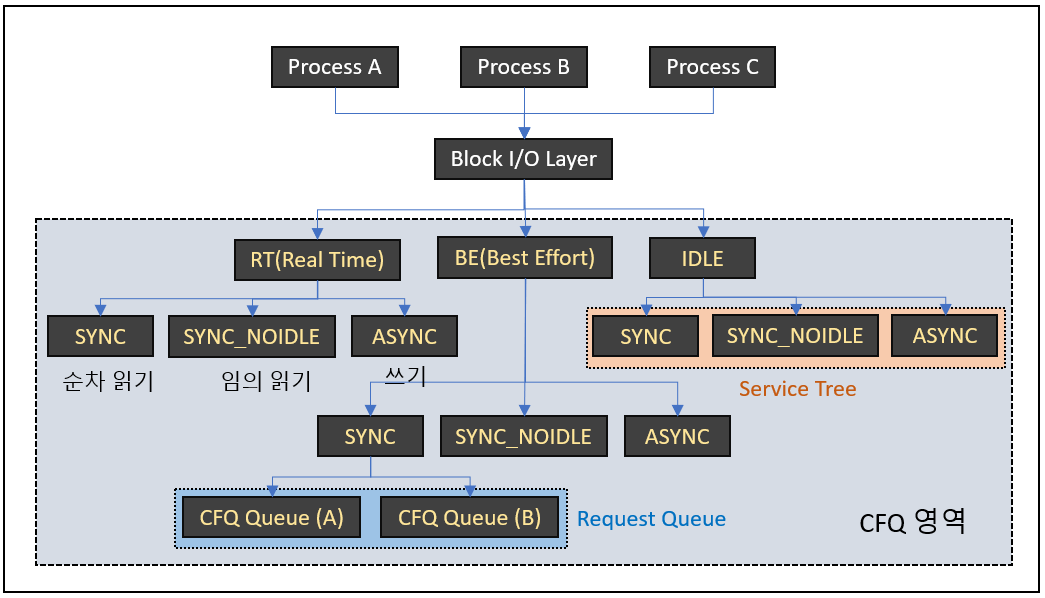
위의 사진으로 과정을 살펴보겠습니다.
프로세스의 I/O 요청은 Block Layer을 거쳐 CFQ로 들어오면서 우선순위에 따라 RT(Real Time), BE(Best Effort), IDLE로 나눠집니다.
RT는 BE와 IDLE보다 항상 먼저 처리되므로, RT에 해당하는 I/O가 많으면 후순위의 요청에서 기아 상태가 발생할 수 있습니다.
RT와 BE는 각 클래스에서 0~7까지의 하위 우선순위로 나누어집니다.
IDLE 클래스는 다른 우선순위 클래스에 대기중인 I/O 요청이 없을 때 처리됩니다.
우선순위 클래스가 분류된 이후 service tree라고 불리는 워크로드별 그룹(SYNC, SYNC_NOIDLE, ASYNC)으로 다시 나눠집니다.
이후 I/O 작업을 요청한 프로세스에 따라 요청이 들어올 cfq queue가 결정되고, 각각 동등한 time slice를 할당하여 round-robin으로 처리가 됩니다.
SYNC : 순차적 동기화 I/O 작업으로 '순차 읽기' 또는 'Direct wirte'을 의미합니다. 순차 작업이므로, 이후 발생할 I/O 요청이 이전의 디스크 섹터와 인접할 가능성이 큽니다. 즉, 큐의 작업을 처리한 후 일정 시간동안 대기하여 현재 헤드의 위치에서 인접한 섹터의 I/O 요청을 기다렸다가 처리합니다.
SYNC_NOIDLE : 임의적 동기화 I/O 작업으로, '임의 읽기'를 의미합니다. 임의 작업은 다음 I/O 요청의 디스크 섹터를 예측할 수 없기 때문에 대기 시간 없이 바로 헤드를 이동합니다.
ASYNC : 비동기 I/O 작업으로 '쓰기 작업(Buffered write)'를 의미합니다. 각 프로세스에서 발생한 쓰기 작업은 이곳에 모여서 한 번에 처리됩니다.
※ 대부분의 요청은 BE에 해당하며 ionice 명령어로 우선 순위 설정 변경 가능
2.2 Deadline I/O 스케줄러
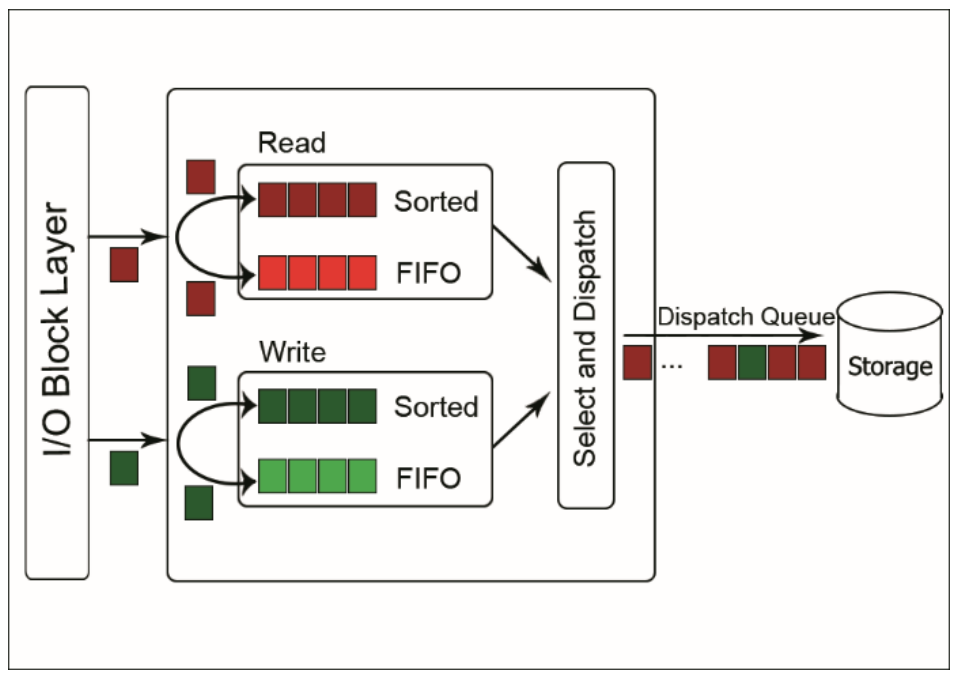
Deadline 스케줄러는 I/O 요청별로 완료되어야 하는 deadline을 가지고 있으며, 리눅스의 starvation(기아 현상) 문제에 대해 가장 빠른 스케줄러입니다.

Deadline 스케줄러에는 2개의 sorted list와 FIFO list가 존재합니다.
sorted list는 각각 읽기 요청과 쓰기 요청을 저장하고 있으며, '디스크 섹터'를 기준으로 정렬됩니다.
FIFO list도 각각 읽기 요청과 쓰기 요청을 저장하지만, '요청이 발생한 시간에 따른 deadline'을 기준으로 정렬됩니다.
Deadline 스케줄러에서 처리되는 I/O 요청이 deadline을 넘지 않는다면, sorted list의 순서대로 처리됩니다.
그러나 deadline을 초과한 I/O 요청이 발생한다면, 해당 요청을 먼저 처리합니다.
예를 들어, sorted list에 각 요청이 섹터 1, 10, 30, 50, 70에 해당하는 순서대로 정렬되어 있다고 가정하겠습니다.
이대로 deadline을 넘는 요청이 없다면, 1 → 10 → 30 → 50 → 70의 순서대로 처리될 것입니다.
여기서 10번 블록의 요청을 처리한 후, 50번 블록에 대한 요청에서 timeout이 발생했다면, 해당 요청을 먼저 처리하기 위해 30 → 50 → 70 의 순서가 아닌 50 → 30 → 70 순서대로 재정렬됩니다.
2.3 NOOP I/O 스케줄러

NOOP 스케줄러는 정렬 없이 병합 작업만 하는 스케줄러로, 아래의 경우에 주로 사용합니다.
- 다른 I/O 스케줄러와 성능 비교
- Storage 자체에 스케줄러가 존재하는 경우 (Intelligent storage 또는 multipath 환경)
- VM을 호스팅하는 경우 (Host와 VM의 스케줄러가 각각 동작하므로 성능 저하가 발생할 수 있음)
- SSD를 사용하는 경우 (특정 섹터에 도달하는데 필요한 시간이 모두 동일하므로, 불필요한 정렬 작업을 하지 않음)
3. Multiqueue 스케줄러

기존의 HDD는 디스크 헤드의 물리적 이동 시간으로 인한 병목 때문에 random access에 한계가 존재했습니다.
그러나 멀티 프로세서 시스템과 SSD가 등장하고 성능이 향상되면서 병렬 처리와 함께 빠른 처리가 가능해졌지만, 기존의 single queue에는 아래와 같은 문제점들이 존재했습니다.
- 데이터 무결성을 위한 queue의 상호배제에서 CPU 간 경합 발생
- I/O request queue를 처리하는 CPU(위 그림의 CPU 0)에서 인터럽트로 인한 잦은 context switching이 발생하는 문제
- 멀티 프로세서 환경으로 인한 NUMA의 Remote Access 문제
- NUMA의 Remote Access : 멀티 프로세서 환경은 기본적으로 2개의 CPU가 사용되는데, 현재 동작 중인 CPU가 다른 NUMA(Node, Node = CPU + Memory)의 메모리에 접근하는 것

결국 single queue는 또 다른 병목이 되었고, 이러한 문제들을 개선하기 위해 software staging queue와 hardware dispatch queue 이렇게 2가지 queue를 가진 Multiqueue(mq)가 등장하였습니다.
software staging queue는 CPU core 또는 소켓 단위에 매핑되어, 각 프로세스들의 I/O 요청을 buffering하고 인접한 섹터의 요청들을 병합하여 I/O 작업을 스케줄링합니다.
이후 각 스케줄러의 로직에 맞게 처리한 후, 자신과 매핑된 hardware dispatch queue로 보냅니다.
hardware dispatch queue는 저장장치의 버퍼가 넘치지 않도록 속도를 조절하여 I/O 요청을 드라이버(Submission queue)로 넘겨줍니다.
hardware queue의 개수는 driver마다 다르지만, 최대 CPU core 개수를 넘을 수 없습니다.
또한 Multi-Queue는 Single-Queue와 달리 I/O 작업에 tagging을 사용합니다.
Driver는 Userspace에서 요청한 I/O 작업을 끝내면, 고유 정수값을 completion tag로 사용하여 block layer에 넘겨줌으로써 어떤 I/O 요청이 완료되었는지 탐색하는 작업을 줄일 수 있습니다.
3.1 BFQ(Budget Fair Queueing) I/O 스케줄러
BFQ 스케줄러는 CFQ 기반이지만, 고정된 time slice가 아니라 섹터의 수에 따라 계산되는 budget을 각 프로세스에 할당하여 I/O batch를 스케줄링합니다.
BFQ는 각 프로세스나 스레드에 대해 별도의 큐를 생성하고, 각 큐에다가 동적으로 조정될 수 있는 예산을 할당합니다.
이 예산은 해당 큐가 디스크에 접근할 수 있는 I/O 자원의 양을 결정합니다.
스케줄러는 큐 간에 라운드 로빈 방식으로 예산을 분배하며, 각 큐는 할당된 예산 내에서 요청을 처리합니다.
예산이 소진되면 다음 큐로 넘어가며, 필요 시 예산을 재분배합니다.
이로써 하나의 Application이 모든 I/O 대역폭을 사용하지 못하도록 보장하며, I/O 처리량보다는 낮은 Latency에 더 초점을 맞춥니다.
주로 스트리밍 서비스와 같이 latency나 loss에 민감한 real-time 시스템에 적합합니다.
3.2 kyber I/O 스케줄러
kyber 스케줄러는 동기 작업인 read와 비동기 작업인 write에 해당하는 2개의 queue로 구성됩니다. 그리고 각 작업의 target latency를 설정하고, 이를 충족하기 위해 동적으로 I/O 요청의 속도나 빈도를 동적으로 조절합니다.
여기서 kyber는 토큰을 사용하여 I/O 처리 시간을 제한합니다.
그리고 Read와 Write에 해당하는 각 토큰이 유효할 때까지 round-robin으로 hardware queue로 dispatch합니다.
토큰의 개수가 많을수록 I/O 작업을 보장받을 수 있는 시간이 길어지므로, target latency를 달성하기 쉬워집니다.
현재 I/O의 latency가 target latency보다 작다면, 이미 target latency를 달성하고 있는 상태이므로 현재 토큰 개수를 유지합니다.
반대로 현재 I/O latency가 target latency보다 크다면, 토큰 개수를 증가시켜서 I/O 작업 시간을 늘림으로써 target latency를 달성할 수 있도록 합니다.
목차
https://hopulence.tistory.com/43
[커널이야기] 리눅스 I/O 스케쥴러
드디어 어려워서 계속 미뤄왔던 남은 마지막 챕터를 정리하네요. 이 포스팅은 아래 책을 정리하며 공부한 내용입니다. 좋은 책을 출판해주신 저자님께 감사드립니다 😊http://www.yes24.com/Product/Goo
hopulence.tistory.com
'시스템 프로그래밍 > 리눅스' 카테고리의 다른 글
| 리눅스 모듈 종류 및 모듈 적용 방법 (0) | 2024.10.14 |
|---|---|
| 리눅스 커널 컴파일 방법 (0) | 2024.10.11 |
| 리눅스 프로세스 스케줄링, 프로세스 스케줄러의 종류 및 동작 방식 (0) | 2024.10.10 |
| 리눅스 fork와 thread의 차이점과 및 예제 (1) | 2024.10.08 |
| 리눅스 디렉토리 구조 파악하기 (1) | 2024.10.02 |
